Видео с ютуба Kv Cache Disk

The KV Cache: Memory Usage in Transformers

KV Cache: The Trick That Makes LLMs Faster
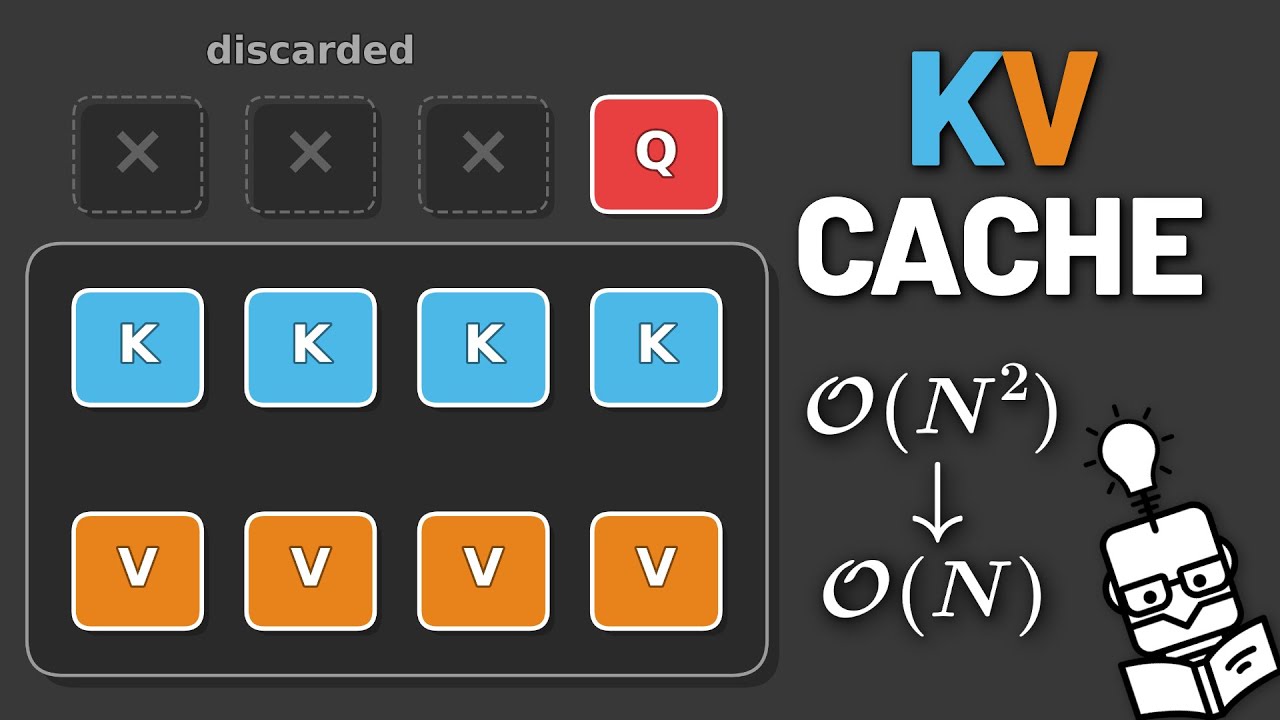
KV Cache - Explained

Кэш KV за 15 мин

Tutorial: KV-Cache Wins You Can Feel: Building AI-Aware... Tyler S, Kay Y, Vita B, Nili G & Maroon A

How to make LLMs fast: KV Caching, Speculative Decoding, and Multi-Query Attention | Cursor Team
![KV Caching: Speeding up LLM Inference [Lecture]](https://imager.clipsaver.ru/_quDGLpNols/max.jpg)
KV Caching: Speeding up LLM Inference [Lecture]
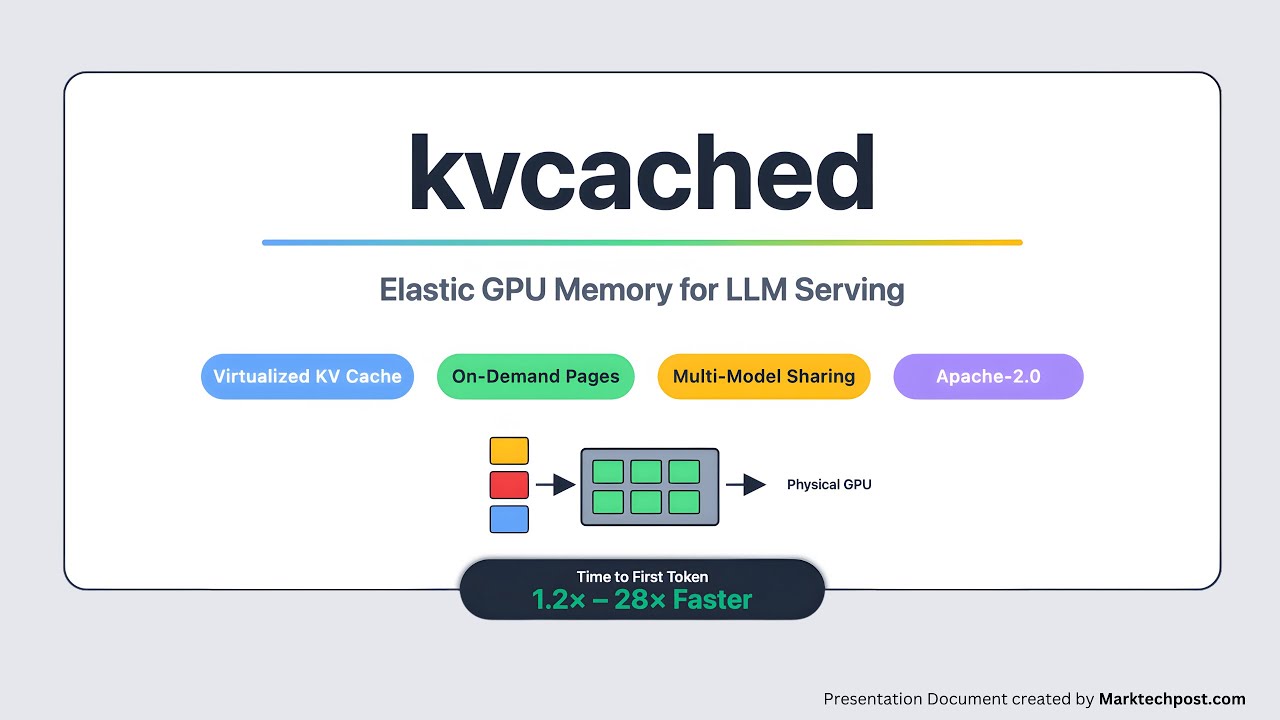
Meet kvcached (KV cache daemon): a KV cache open-source library for LLM serving on shared GPUs

Внимание, KV-кэш, MQA и GQA — визуальное руководство

KV Cache: The Invisible Trick Behind Every LLM

Нам больше не нужен KV-кэш?

🚀 KV Cache Explained: Why Your LLM is 10X Slower (And How to Fix It) | AI Performance Optimization

KV Cache: The one trick making LLMs 100x faster
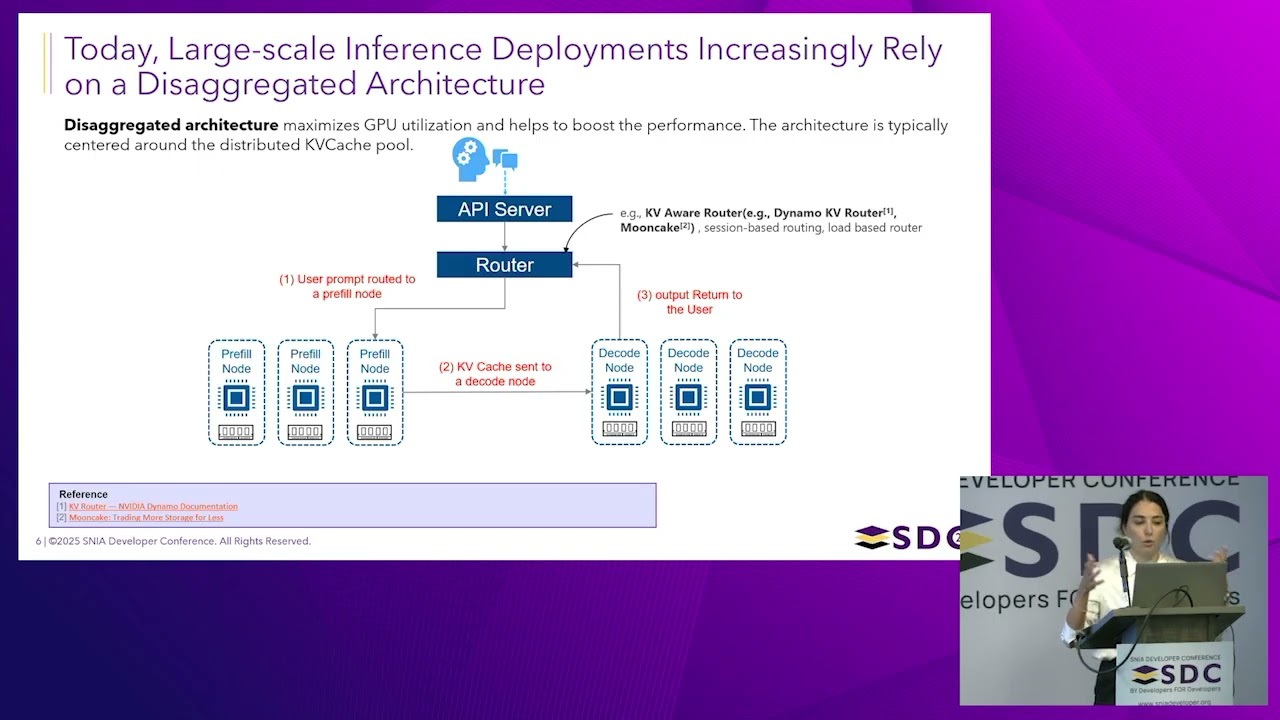
SNIA SDC 2025 — Разгрузка хранилища KV-кэша для эффективного вывода в LLM

Масштабирование вывода LLM с помощью многоуровневого кэширования: расширение LMCache с помощью Am...
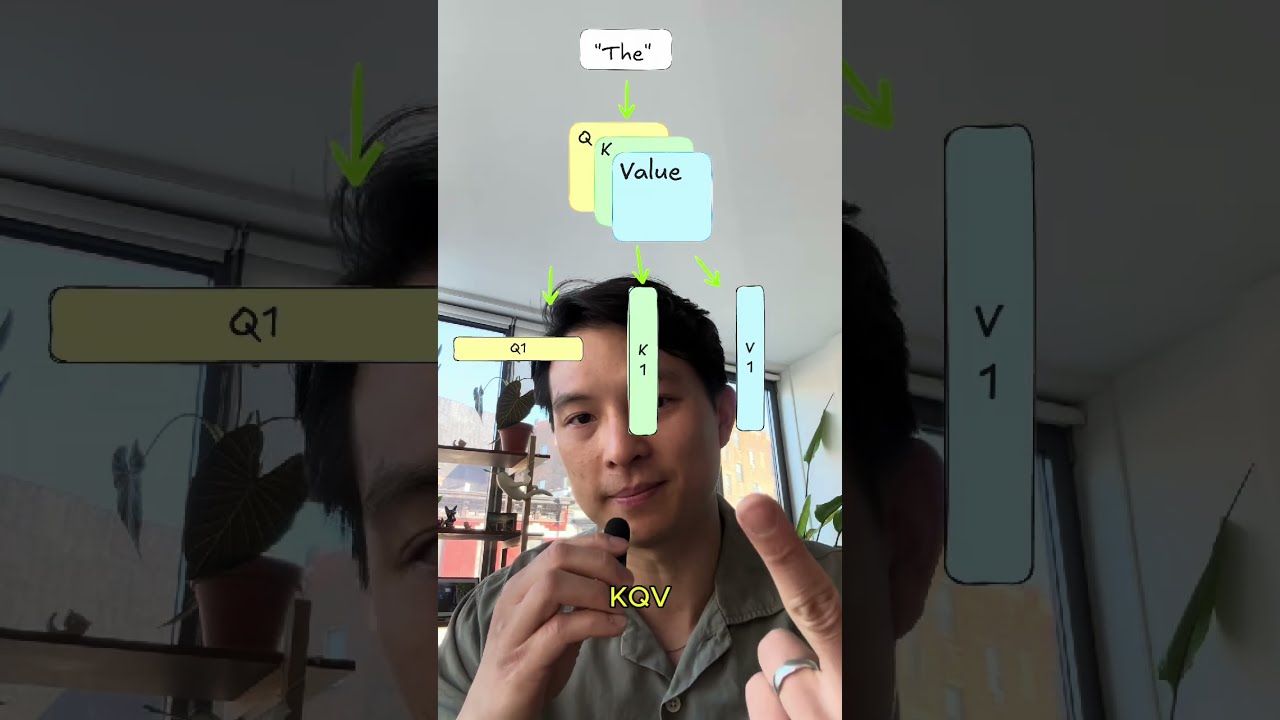
Объяснение кэша KV

Как кэш KV ускоряет работу LLM? | Важно знать

Инференс с упором на KV-кэш: создание платформы обслуживания LLM с открытым исходным кодом вокруг...

Как кэш ключ-значение влияет на производительность ИИ: Solidigm объясняет скрытый путь каждого за...

Кэш ключ-значение: упрощение работы с большими языковыми моделями.